大數據到底怎么學:以數據處理為核心的系統化路徑
隨著數據成為新時代的“石油”,掌握大數據技能已成為眾多從業者提升競爭力的關鍵。面對龐雜的技術棧和快速迭代的工具,許多學習者容易陷入誤區,或盲目跟風,或停滯不前。本文將從數據科學的基本框架出發,聚焦數據處理這一核心環節,澄清常見的學習誤區,為你勾勒一條清晰、高效的大數據學習路徑。
一、數據科學概論:理解全景圖
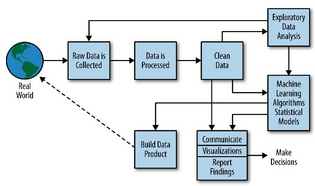
數據科學是一個跨學科的領域,它結合了統計學、計算機科學和特定領域的專業知識,旨在從數據中提取洞見并創造價值。一個經典的數據科學流程(如CRISP-DM)通常包括:
- 業務理解:明確要解決的商業或研究問題。
- 數據獲取與理解:收集相關數據并進行初步探索。
- 數據準備(數據處理):這是承上啟下的核心步驟,包括數據清洗、集成、轉換、規約等,旨在將原始數據轉化為適合建模的格式。
- 建模:應用算法構建模型。
- 評估:驗證模型的有效性。
- 部署:將模型投入實際應用。
可見,數據處理的質量直接決定了后續所有環節的上限。沒有干凈、可靠的數據,再精巧的模型也是“垃圾進,垃圾出”。
二、大數據學習的核心:深入掌握數據處理
數據處理是大數據技術棧的基石。學習時應分層遞進:
1. 基礎層:編程與SQL
Python/R:這是數據科學的通用語言。重點學習用于數據處理的庫,如Python的Pandas(數據操作)、NumPy(數值計算)。
SQL:用于從數據庫中高效提取和初步處理數據。這是與數據對話的必備技能,無論技術如何演進,其地位不可動搖。
2. 核心層:大數據處理框架與平臺
Hadoop生態:理解其分布式存儲(HDFS)和計算(MapReduce)的基本思想。
Spark:作為當前的主流,重點學習其核心抽象(RDD、DataFrame/Dataset)和使用PySpark或Spark SQL進行大規模數據處理。相比MapReduce,Spark在內存計算上的優勢使其成為數據處理的首選工具之一。
* 數據倉庫與湖倉一體:了解Hive、ClickHouse、Snowflake等概念,理解如何為分析而組織和處理數據。
3. 實踐層:工程化與流程管理
學習使用Airflow等工具編排數據處理流水線(ETL/ELT)。
了解數據質量監控、版本控制(如Delta Lake)等生產級數據處理所需的知識。
三、必須規避的常見大數據學習誤區
誤區一:重模型,輕數據。
盲目追求最新的深度學習模型,卻忽視了占項目80%時間的數據處理工作。務必樹立“數據第一”的觀念,扎實練好數據清洗、特征工程等基本功。
誤區二:重工具,輕原理。
沉迷于學習各種新工具的名詞,卻不理解分布式計算、并行處理、列式存儲等底層原理。這會導致遇到復雜問題時無從下手。建議在學習Spark等工具時,同步理解其架構思想和設計原理。
誤區三:缺乏系統性,碎片化學習。
東學一點SQL,西看一點Spark教程,知識無法串聯。建議以一個完整的項目(如“從日志數據中分析用戶行為”)驅動學習,覆蓋從數據采集、清洗、存儲、處理到可視化的全流程。
誤區四:脫離業務場景。
技術學習與實際問題脫節。數據處理的方法千變萬化,其目標始終是服務于業務分析或模型構建。在學習每個技術點時,多問一句“這解決了什么業務痛點?”
誤區五:忽視數據治理與倫理。
只關注技術實現,不考慮數據安全、隱私保護、偏見消除等問題。這是專業數據科學家與普通技術員的區別所在。
四、推薦的學習路徑與心態
- 夯實基礎:花足夠時間精通Python(Pandas)和SQL。這是你行走數據世界的“雙腿”。
- 原理先行:在學習Hadoop/Spark前,先理解分布式系統基礎概念。
- 項目驅動:找感興趣的數據集(如Kaggle、公開政府數據),完成一個端到端的項目,將數據處理作為項目的核心環節來重點實踐。
- 深入核心:選擇Spark作為重點,深入學習其API和優化技巧,理解其在內存中完成數據處理的強大之處。
- 構建知識體系:將數據處理技能與數據存儲(HDFS、HBase)、資源管理(YARN)、調度(Airflow)等周邊知識連接起來。
- 保持好奇與批判:關注行業動態,但同時批判性地看待新技術,判斷其是否真正解決了數據處理中的效率或質量瓶頸。
學習大數據沒有捷徑,但可以有清晰的路線圖。請牢記,數據處理是這條路上的樞紐站。避開常見誤區,沉下心來打好基礎,通過實踐將原理、工具和業務串聯起來,你便能穩步構建起堅實的大數據能力大廈,從而真正駕馭數據,創造價值。