數(shù)據(jù)倉庫作為企業(yè)數(shù)據(jù)分析的核心基礎設施,其發(fā)展歷程經(jīng)歷了從傳統(tǒng)架構到現(xiàn)代云原生技術的演進。海山數(shù)據(jù)庫(He3DB)作為新一代數(shù)據(jù)倉庫解決方案,其設計理念和技術架構深刻吸收了傳統(tǒng)數(shù)據(jù)倉庫的經(jīng)驗與教訓。本文作為系列文章的第一部分,將聚焦傳統(tǒng)數(shù)據(jù)倉庫的數(shù)據(jù)處理模式,為理解He3DB的架構演進奠定基礎。
傳統(tǒng)數(shù)據(jù)倉庫誕生于20世紀80年代末至90年代初,其核心目標是整合企業(yè)內(nèi)部分散的異構數(shù)據(jù)源,構建統(tǒng)一的數(shù)據(jù)視圖以支持決策分析。在數(shù)據(jù)處理層面,傳統(tǒng)數(shù)倉遵循經(jīng)典的ETL(Extract-Transform-Load)流程:首先從業(yè)務系統(tǒng)(如ERP、CRM等)抽取數(shù)據(jù),然后進行清洗、轉(zhuǎn)換和集成處理,最終加載到專門優(yōu)化的數(shù)據(jù)存儲中。這種批處理模式通常以夜間作業(yè)的形式進行,確保第二天上班前完成數(shù)據(jù)更新。
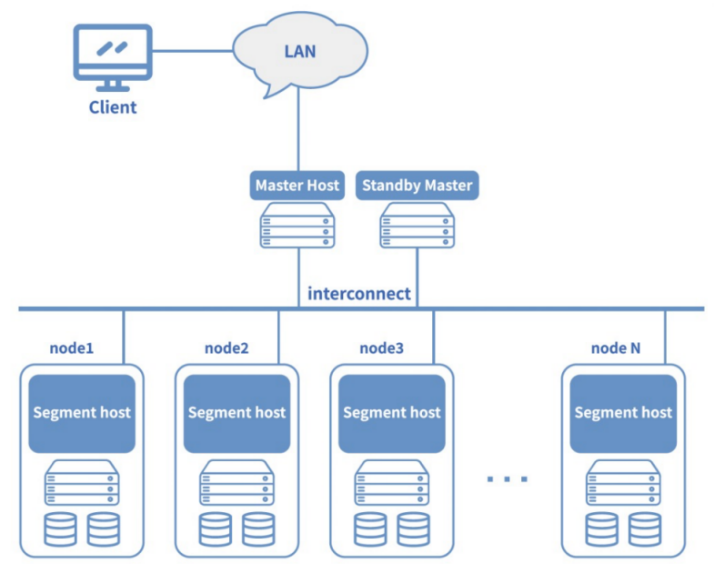
在技術架構上,傳統(tǒng)數(shù)倉多采用集中式的存儲與計算耦合設計。典型代表包括Teradata、Oracle Exadata等一體機解決方案,它們通過大規(guī)模并行處理(MPP)架構提升查詢性能。數(shù)據(jù)處理的核心挑戰(zhàn)集中在以下幾個方面:數(shù)據(jù)延遲問題突出,T+1的數(shù)據(jù)更新頻率難以滿足實時分析需求;擴展性受限,硬件升級成本高昂且存在性能瓶頸;數(shù)據(jù)類型支持單一,主要針對結構化數(shù)據(jù),難以處理半結構化和非結構化數(shù)據(jù)。
傳統(tǒng)數(shù)倉的數(shù)據(jù)建模通常采用維度建模方法,以星型模式或雪花模式組織數(shù)據(jù)。這種設計雖然提升了查詢效率,但也導致了數(shù)據(jù)冗余和維護復雜性。在數(shù)據(jù)治理方面,傳統(tǒng)數(shù)倉建立了嚴格的數(shù)據(jù)質(zhì)量管控流程,但往往缺乏靈活的數(shù)據(jù)探索和即席查詢能力。
隨著大數(shù)據(jù)時代的到來,傳統(tǒng)數(shù)據(jù)倉庫在應對海量數(shù)據(jù)、實時分析和多樣化數(shù)據(jù)類型方面逐漸顯現(xiàn)出局限性。正是這些挑戰(zhàn)催生了新一代數(shù)據(jù)倉庫技術的創(chuàng)新,也為海山數(shù)據(jù)庫(He3DB)的架構設計提供了重要參考。在后續(xù)文章中,我們將深入探討He3DB如何基于這些傳統(tǒng)架構的洞察,構建更現(xiàn)代化、更高效的數(shù)據(jù)處理體系。